
🎧🎧🎤🎤
1. 概要
[语音识别][1]:利用计算机将语音信号转化为对顶其内容的文本,语音识别是一个交叉学科,它的应用也表现在很多方面,互联网时代语音识别作用越来越广,它渐渐成为互联网的入口.
语音识别系统框图:
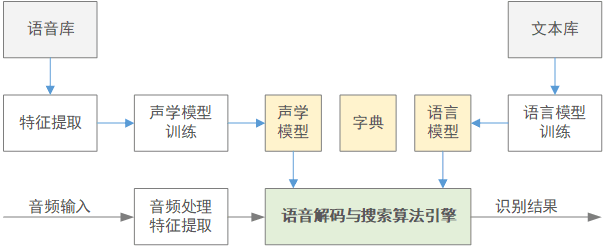
主要分为[特征提取,声学模型,发音字典,语言模型][2],其中声学模型和语言模型是在训练阶段得到的.声学模型由大量带标注的语言信号训练得来.语言模型则是通过大量的文本信号经过统计方法得到.
解码阶段解码器综合了声学模型发音字典和语言模型等等知识元对测试语音进行打分,并经过最优路径搜索得到最优的词序列.解码就是给定观测序列O的条件下求取最优词序列W的过程,进一步可以通过贝叶斯公式展开.可以得到声学模型自然度和语言模型先验概率乘积的形式
\begin{align} \hat{W}&=arg maxP(W|O)=arg max\frac{P(O|W)P(W)}{P(O)}\\ &=arg maxP(O|W)P(W) \end{align}
语音识别各模块的作用:
-
特征提取:通过信号处理手段将原始的语音波形转换成特征矢量序列,作为语音识别系统的输入;语音识别系统信号常用16kHz/8kHz采样,常用25ms帧长,10ms帧移;常用特征提取:MFCC,PLP,fbank等短时频谱特征.(将语音信号的时域波形首先转换成平域信号,在经过一些信号处理手段,滤波,[离散余弦变换][1]等得到最终的语音特征)https://zhuanlan.zhihu.com/p/85299446
-
声学模型:对语音特征进行刻画的模型,它是一个概率模型,刻画语音片段的属性声学建模技术是语言识别系统中的一个关键技术,他对系统的性能起着重要的作用.最常见的声学模型是[隐马尔科夫][2](Hidden Markov Model,HMM)模型,隐马尔可夫模型被用来处理语音声学序列的时间特征.https://zhuanlan.zhihu.com/p/63753017
建模单元:每一个基本的语言建模单元(单词,音素,三音素)对应一个HMM.
拓扑结构:从左到右三状态,状态一到状态五是虚拟状态用于连接前后的HMM,状态2,3,4是实际的HMM物理状态.
HMM中的两个序列:
每个状态定义了两个分布,第一从状态到观测的分布,HMM的发射概率b.第二是状态之间的跳转分布,HMM的转移概率a.每一个物理状态都可以跳转到自身或者跳转到下一个状态因此转移概率是一个离散的概率分布,而观测概率分布则是一个连续的概率分布.HMM的性能主要由发射概率来决定.传统的声学建模中经常使用高斯混合模型GMM来建模HMM的发射概率.而在基于深度学习的声学建模方法中常使用深度神经网络来建模HMM的发射概率模型.
状态序列S={,,..., }
观测序列O={,,..., }

-
发音字典:是连接声学模型和语言模型的桥梁,发音字典包含了词(word)到声学建模单元(音素)的映射.语音识别中称声学建模单元为音素.将词汇表里所有的词对应的发音都总结在一起便构成了发音字典.
-
语言模型:是语言识别系统中一个不可或缺的模型.因为人说话往往有一定的意义,符合一定的语言规律因此通过使用语言模型可以很好的和解码器结合引导搜索的算法,并且语言模型还可以对相似的发音进行区别.最常使用的是N-gram语言模型.该模型使用了马尔科夫假设,即第N个词的概率只和前N-1个词相关.
N-gram语言模型:
-
解码和搜索:解码器的好坏以及效率如何直接关系到了语音识别系统的快慢.在语音识别系统中发音字典语言模型和声学模型构成一个潜在的巨大的解码网络.
动态解码算法:解码网络动态生成
静态解码算法:是事先生成的,空间换时间,速度快.加权有限状态机(WFST)对声学模型H,因素上下文关系C,发音字典L,语言模型G做一个统一的图表示.得到HCLG再通过合成操作,确定化操作,最小化操作等得到最终的解码网络,在该解码网络上进行搜索就是静态解码器的最基本的原理.
一遍解码:一套模型对语言信号进行搜索.
多遍解码:使用一套小的模型.首先解码出一个包含多路径的词格,再使用较大的模型在词格上进行搜索,多遍解码得到更好的效果.
2. 研究现状
2.1 [GMM-HMM][2]
20世纪80年代至今,语音识别三大基石:隐马尔克夫模型,高斯混合模型和MFCC/PLP短时特征.https://zhuanlan.zhihu.com/p/71949938
2.2 DNN-HMM
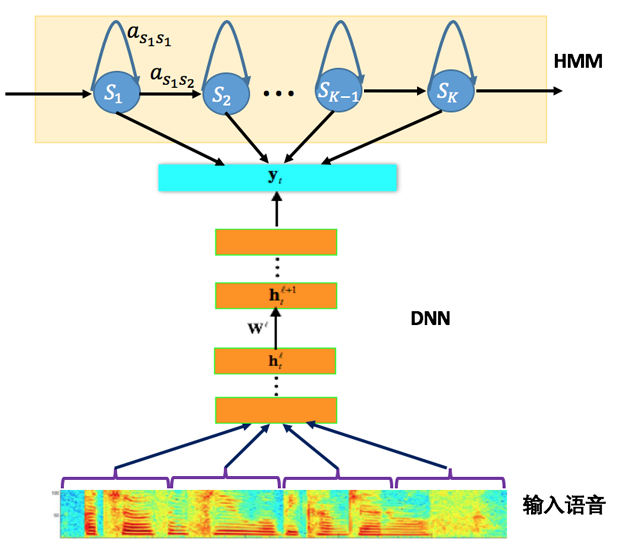
2011年,基于深层神经网络(DNN)的DNN-HMM声学模型建模技术出现,极大地提高了语音识别系统的性能.转移概率不变,发射概率DNN进行建模和估计.三大特点:
- 使用深层神经网络直接对HMM的三因素进行建模,状态参数互相共享,使用统一的目标函数,多个隐含层同时进行特征提取和模式分类,模型参数更加有效.
- 使用多个隐含层的神经网络,建模能力随着网络的层数和每层的节点数的增多而增强.
- 使用长时间的输入窗来作为神经网络的输入.
2.3 卷积神经网络(CNN)声学模型
语谱图:明暗相间的条纹代表共振峰,明暗相间的条纹具有一定的局部性,频域:局部信息;时间轴可以看出语谱图具有一定的连续性.时域:长时信息.在输入层使用局部连接的权重对语言信号频率上的各个子代进行建模,因此这个结构能够很好的刻画语音信号的局部特征,当得到各个子代的神经网络输出之后,再maxpoling操作进行对子代的输出进行降维.不同人说话呢的共增峰位置不同,加入maxpoling能够很好的捕捉不同人语音的共振峰位置,因此能够增强鲁棒性提高识别性能.不同子代的神经网络输出被拼接到一起送入全连接层.
2.4 递归神经网络(RNN)声学模型
为了建模语言信息时域上的长时信息,使用了递归连接的权重来建模时域的上下文关系,递归神经网络可以进一步在时域上进行展开,无论是在空间的变换域还是在时域都是一个深层的神经网络
2.5 长短时记忆递归神经网络(LSTM RNN)声学模型
解决时间维度的梯度消失问题
3.研究内容
4.创新内容
5.参考文献
[1] 刘长征,张磊.语音识别中卷积神经网络优化算法[J].哈尔滨理工大学学报,2016(3):34-38.
[2] 金超,龚铖,李辉.语音识别中神经网络声学模型的说话人自适应研究[J].计算机应用与软件,2018,35(2):200-205,266.
[3] Cai M,Liu J.Maxout neurons for deep convolutional and LSTM neural networks in speech recognition[J].Science Direct,2016,77:53-64.
[4] 梁玉龙,屈丹,李真,等.基于卷积神经网络的维吾尔语语音识别[J].信息工程大学学报,2017,18(1):44-50.
[5] 杨洋,汪毓铎.基于改进卷积神经网络算法的语音识别[J].应用声学,2018,37(6):108-114.
[6]Fan R C,Liu G.CNN-based audio front end processing on speech recognition[C]//2018 International Conference on Audio,Language and Image Processing(ICALIP),2018:349-354.
[7] 高净植,刘祎,白旭,等.平稳小波域深度残差CNN用于低剂量CT图像估计[J].计算机应用,2018,38(12):236-242.
[8] Jiang W,Zhang L.Geospatial data to images:A deep-learning framework for traffic forecasting[J].Tsinghua Science and Technology,2019,24(1):52-64.
[9]Graves A,Jaitly N.Towards end-to-end speech recognition with recurrent neural networks[C]//International Conference on Machine Learning.2014:1764-1772.
[10] 王庆楠,郭武,解传栋.基于端到端技术的藏语语音识别[J].模式识别与人工智能,2017(4):73-78.
[11] 姚煜,Chellali R.基于双向长短时记忆-联结时序分类和加权有限状态转换器的端到端中文语音识别系统[J].计算机应用,2018,38(9):2495-2499.
[12] 于重重,陈运兵,孙沁瑶,等.基于动态BLSTM和CTC的濒危语言语音识别研究[J].计算机应用研究,2019,36(11):3334-3337.
[13] Tan T,Qian Y,Hu H,et al.Adaptive very deep convolutional residual network for noise robust speech recognition[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2018,26(8):1393-1405.
[14]Qian Y,Woodland P C.Very deep convolutional neural networks for robust speech recognition[C]//Spoken Language Technology Workshop.IEEE,2017.
[15]张瑞珍,韩跃平,张晓通.基于深度LSTM的端到端的语音识别[J/OL].中北大学学报(自然科学版),2020(02):244-248[2020-04-24].http://kns.cnki.net/kcms/detail/14.1332.TH.20200421.1336.002.html.
[16]刘娟宏,胡彧,黄鹤宇.端到端的深度卷积神经网络语音识别[J].计算机应用与软件,2020,37(04):192-196.